CSS 如何运行
当浏览器展示一个文件的时候,它必须兼顾文件的内容和文件的样式信息,下面我们会了解到它处理文件的标准的流程。需要知道的是,下面的步骤是浏览加载网页的简化版本,而且不同的浏览器在处理文件的时候会有不同的方式,但是下面的步骤基本都会出现。
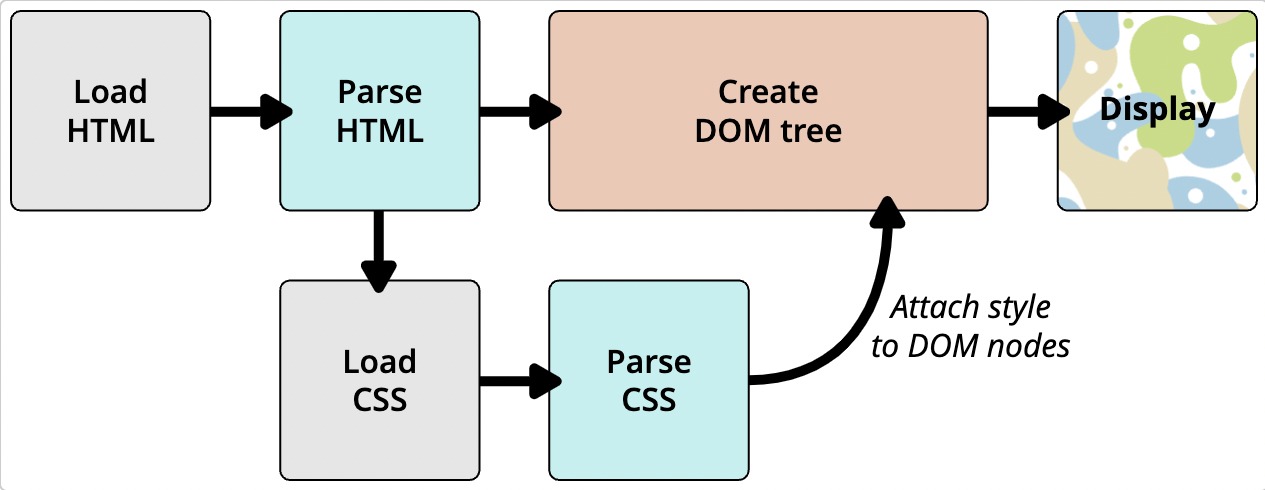
- 浏览器载入 HTML 文件(比如从网络上获取)。
- 将 HTML 文件转化成一个 DOM(Document Object Model),DOM 是文件在计算机内存中的表现形式,下一节将更加详细的解释 DOM。
- 接下来,浏览器会拉取该 HTML 相关的大部分资源,比如嵌入到页面的图片、视频和 CSS 样式。JavaScript 则会稍后进行处理,简单起见,同时此节主讲 CSS,所以这里对如何加载 JavaScript 不会展开叙述。
- 浏览器拉取到 CSS 之后会进行解析,根据选择器的不同类型(比如 element、class、id 等等)把他们分到不同的“桶”中。浏览器基于它找到的不同的选择器,将不同的规则(基于选择器的规则,如元素选择器、类选择器、id 选择器等)应用在对应的 DOM 的节点中,并添加节点依赖的样式(这个中间步骤称为渲染树)。
- 上述的规则应用于渲染树之后,渲染树会依照应该出现的结构进行布局。
- 网页展示在屏幕上(这一步被称为着色)。
什么是 DOM
Document Object Model
一个 DOM 有一个树形结构,标记语言中的每一个元素、属性以及每一段文字都对应着结构树中的一个节点(Node/DOM 或 DOM node)。节点由节点本身和其他 DOM 节点的关系定义,有些节点有父节点,有些节点有兄弟节点(同级节点)。比如以下的 HTML 代码:
<p> |
在这个 DOM 中,<p> 元素对应了父节点,它的子节点是一个 text 节点和三个对应了 <span> 元素的节点,SPAN节点同时也是他们中的 Text 节点的父节点。
P |
CSS Bug
浏览器遇到无法解析的 CSS 会发生什么?答案就是浏览器什么也不会做,继续解析下一个 CSS 样式!
如果一个浏览器在解析你所书写的 CSS 规则的过程中遇到了无法理解的属性或者值,它会忽略这些并继续解析下面的 CSS 声明。在你书写了错误的 CSS 代码(或者误拼写),又或者当浏览器遇到对于它来说很新的还没有支持的 CSS 代码的时候上述的情况同样会发生(直接忽略)。
相似的,当浏览器遇到无法解析的选择器的时候,他会直接忽略整个选择器规则,然后解析下一个 CSS 选择器。